意思決定アルゴリズム
目次
概要 †
AIが自分自身でするべきことを判断・創造する技術を「意思決定」と言う。現段階では、人間の知能をそのまま人工知能で実現することは難しいため、意思決定は、人間の知能のさまざまな側面を抽出して実現することとなる。
7つのアルゴリズム †
ゲームAIで使う代表的な意思決定の方法はつぎの7つ。なお、ここで言う「○○ベース」とは、「○○という形式を基本として意思決定を組み立てているAI」のことを指す。それぞれ長所と短所、実装に適した場面があるが、7つとも現在も使われているアルゴリズムだ。
アルゴリズム1:ルールベースAI †
「もし〜だったら、〜である(If-then)」というルールを基本として組み立てられるAI。ゲームの場合は「味方のHPが20%を切ったら回復させる」、「攻撃力の高い敵を攻撃する」など、複数のルールを選択し、あるいは組み合わせることでキャラクターAIの行動を決定づける。
だが実際にゲームに実装した場合、つぎのようなことが起こる可能性がある。
たとえばHPが20%を切り強力な攻撃を受ければ一撃で戦闘不能になる味方がいて、かつ攻撃力の高い敵もまたHPが低い状態にあるとする。このような状態で味方が戦闘不能になることを避けるためには、味方のHPを回復させる、もしくは攻撃力の強い敵を先に撃破するという具合に、次に選ぶべき選択肢が複数生じる。このように、選択可能(条件を満たし発火可能)な複数のルールがあった場合、それらの中からどれを選択するかを決定するモジュールを「ルールセレクター」と呼ぶ。
ルールセレクターの選択方法は、実行可能なものの中からランダムに選ぶ、あるいはあらかじめ優先順位を決めておく、直前にした選択肢を次は選択しないなど、複数考えられる。

引用元:Modeling Individual Personalities in The Sims 3
アルゴリズム2:ステートベースAI †
ステートとは状態のこと。ステートベースAIとはゲーム世界やキャラクターの行動の連携によって生じる「状態」の集合で表現するAIのことを指す。
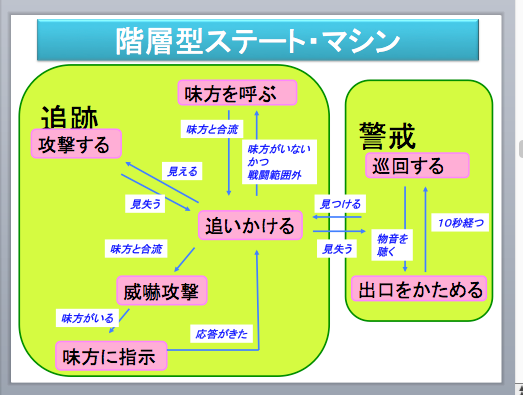
たとえば敵の拠点にいる警備兵の行動を状態で表現しようとするとき、「巡回」、「休憩」、「追撃」、「攻撃」という4つに分けることができるとする。これをたとえば「巡回する」→「5メートル以上離れた場所に敵を発見する」→「追撃する」→「攻撃する」というフローで示す。このとき「30秒巡回しても敵が見つからない」→「休憩する」となったり、「発見した敵を追撃したが見失う」→「その後5秒探した後、ふたたび巡回に戻る」となったりなど、状態は移り変わる。
こうしたとき、「ある状態から別の状態に変化するトリガーとなる条件」を付けることで、警備兵の知能を表現することができる。このように状態と遷移条件を設定することでキャラクターの行動を記述する方法を「ステートマシン」と呼ぶ。
キャラクターの行動が複雑化する大型のゲームにおいては、ステートと遷移条件が増えすぎることを緩和するために、上位のステートマシンのステートにさらにステートマシンを入れた「階層型ステートマシン」を実装することが多い。
※階層型ステートマシンの概念図(三宅陽一郎氏・作)
※『Quake』におけるステートマシンについて
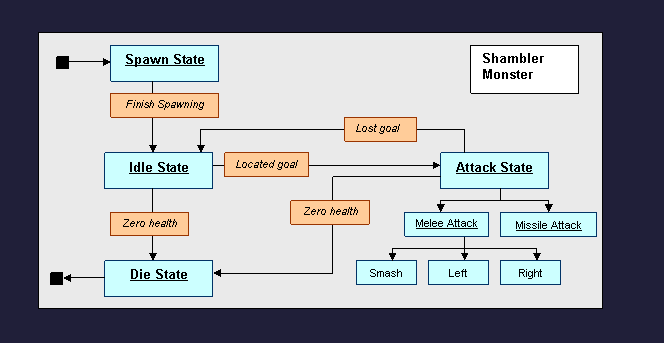
引用元
アルゴリズム3:ビヘイビアベースAI †
キャラクターの身体的行動のレベルでキャラクターの行動を考えることを、ビエイビアベースと言う。その一例であるビヘイビア・ツリーは『Halo2』(2004年/Bungie)のために、Damian Islaによって開発され、現在もっとも多く使われているゲームAIの手法となっている。
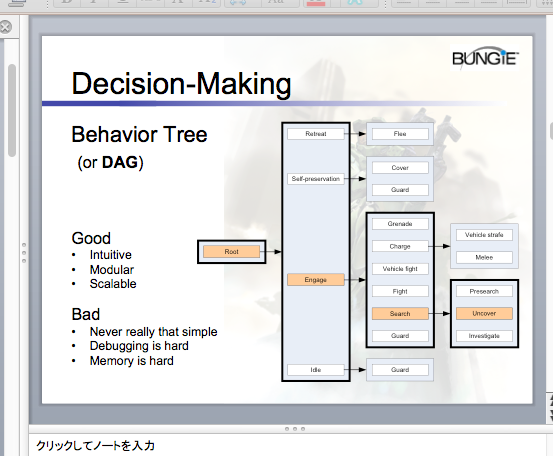
ビヘイビア・ツリーはツリー構造であり、各ノード(枝)がルート(根)から伸びた枝の先にあるという構造を持つ。末端のノードに至るまでには中間ノードを通過するが、中間ノードには行動の実態は伴わず、次のノードの実行順序だけを決定する。
中間ノードには次の5つのモードがある。
- 優先順位リスト法
あらかじめノードの優先度を決め、実行可能なノードのうち、もっとも優先度の高いノードを実行する。 - シークエンス法
あらかじめノードの実行順序を決めておき、実行可能なノードすべてを順番に従って実行する。 - シークエンシャル・ルーピング法
シークエンス法と同じだが、末端まで行くともう一度最初から実行する。 - 確率的方法
実行可能なノードのうち、実行するノードをランダムに選択する。 - オン−オフ法
ランダムに、あるいは優先リストによって実行するノードを選ぶが、一度選んだものを再び選択することはない。
これらのモードが中間に入ることで、それより下位のノードがどの順番で実行されるかが決定される。
ビヘイビア・ツリーはシンプルさと引き替えに、あらかじめ使えるパーツが決まっており、それらを組み合わせた範囲内のことしか実行できない。そのため、現在もゲーム会社ごと、あるいはタイトルごとに多様なバリエーションが作られている。
アルゴリズム4:タスクベースAI †
ある課題を解くときに、抽象的なタスクに分解して物事を解決するAI。たとえば「ドアに鍵のかかった部屋に入る」というタスクは、「鍵のありかを探す」、「鍵を持っている敵を見つけて撃破する」、「鍵を拾う」、「鍵を使ってドアを開ける」、「部屋に入る」というタスクに分解できる。
タスクベースで重要なのは、「タスクの分解」と「タスクの実行順序」の2点。タスクどうしの関係性にはつぎの3つが存在する。
全順序:タスク群の実行順序が完全に決まっている。
局所的順序:タスク群のうち、いくつかの実行順序が決まっている。
非順序:タスク群の実行順序が決まっていない。
たとえば敵の城を攻撃するときに、城の手前にある複数の砦を陥落させないと城の扉が開かないとする。これらの砦を陥落させる順序がとくに決まっていない場合は、局所的順序タスクとなる。この局所的タスクをAIが実行するために、各タスクどうしをネットワーク状にしたものを「タスクネットワーク」と呼ぶ。
なお、状況に応じてタスクネットワークを自動生成する仕組みが「階層型タスクネットワーク(HTN、Hierarchical Task Network)」である。ここでは、あるタスクをより小さなタスクに分解する定義を「メソッド」と呼び、分解したタスクが分岐したものを「ブランチ」と呼ぶ。分解の一過程をひとつの単位にすることで、タスクの追加や入れ替えは容易になる。そのため状況に応じたタスクネットワークを自動的に生成できるのだ。
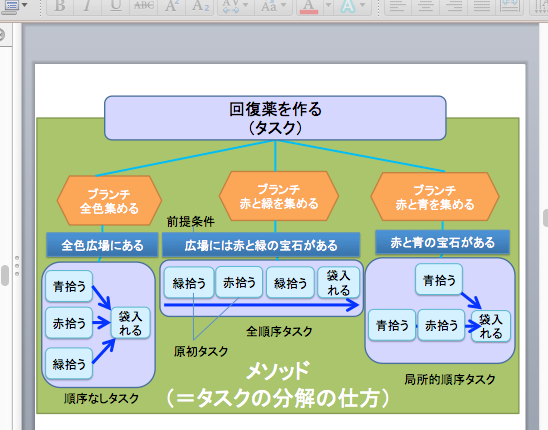
『KILLZONE2』(2011年、Guerrilla Games)は、階層型タスクネットワークを導入したことで、毎秒500個のプランを複数のキャラクターのために自動生成することができるようになった。
参考:『KILLZONE2Multiplayer Bots 』
アルゴリズム5:ゴールベースAI †
目標の達成に向かうことを最優先させるAI。RPGなどで提示されるミッションを達成するためには、ゴールに向かう行動に柔軟性をもたらすゴールベースAIがもっとも適している。
ゴールベースにはふたつの手法がある。ひとつは、大きなゴールを小さなゴールへと分解して、ひとつひとつのゴールを達成していく方法を「階層型ゴール指向プランニング」と呼び、環境の変化に対してすぐに反応するのではなく、最終的なゴールを達成するための長期的な行動の組み合わせを自分で考えて実行するものとなる。ふたつ目は、ゴールを連鎖的に繋いでいくアルゴリズム(ゴール指向アクションプランニング)である。
:
※『F.E.A.R』 におけるゴール指向アクションプランニングの例
参考 †
※『クロムハウンズ』における階層型ゴール指向プランニングの例
※『トゥームレイダー』におけるゴール指向アクションプランニングの例
アルゴリズム6:ユーティリティベースAI †
見返り(ユーティリティ)をもとに行動を決定する思考を抽象化・一般化したAI。デジタルゲームは、プレイヤーのモチベーションを上げるために、リスクが高いほどリターンが高くなるようにデザインされている。たとえば強いモンスターを倒すほど、多くの経験値やお金が手に入るが、何を見返りとするかは、ゲームやゲーム内でプレイヤーが直面している状況によって異なる。
たとえば『クロムハウンズ』(2006年/セガ/フロムソフトウェア)に登場する敵のキャラクターAIは、自動的に武器を選択し、相手との距離に応じてもっとも効果の高い武器を選択するようになっている。
『The Sims』(2000年、Maxis)は、街の中で生活するキャラクターに空腹度、眠れている度、排泄度、寂しくない度、きれい満足度、楽しめている度、快適度、体力度といった生理パラメーターを設けた。たとえば非常に空腹なときは、食事の効用が上がる。ほかの項目も低下しているほど、充足したときの度合いが高くなる。これは経済学の「限界効用逓減の法則」を再現したものであり、それによって最大効果を持つ行動が自動的に選択されるようになる。
参考文献:ゲームプログラミングのための行動AI数学
アルゴリズム7:シミュレーションベースAI †
シミュレーションベースは、まだ実行していない自分の行動をAIに想像させるもの。
ゲーム内の複雑な地形の中でのキャラクターの行動がどのような結果をもたらすかを知るためにシミュレーションを用いる場合がある。たとえば複雑な洞窟の中で魔法攻撃をした場合、どの角度と強さならより遠くに攻撃を飛ばすことができるか、あるいは狭く入り組んだ岩山の隙間をロボットや飛行機が飛ぶときに、どの方向とタイミングでジェット噴射をすれば壁にぶつからずに通り抜けられるか。これらは論理や規則のみで決めるには無理のある事柄であるため、ステートマシンやビヘイビア・ツリーを使うことはできない。シミュレーションベースは、このような場合に役立つアプローチだ。
シミュレーションベースの応用例のひとつは、囲碁AI『AlphaGo』に使用されたことでも知られる「モンテカルロ木探索法」である。ランダムにシミュレーションをしているうちに、相手に勝つ結果が出てくることがあるわけだが、そこで導き出される勝率をそれぞれの手の評価値として、このうちもっとも勝率の良い手を選択する。
具体的な使用例としては、『Total War: Rome II』(2013年/クリエイティブ・アッセンブリー)において、モンテカルロ木探索法に従って、可能な手がシュミレーションされ、最善手が選択されるものがある。
<参考:PFIセミナー2016/04/07:モンテカルロ木探索を使って文生成 >
関連項目 †
キャラクターAI
エージェント・アーキテクチャー
環境認識
ナビゲーションAI
参考文献 †
『人工知能の作り方』 (三宅陽一郎 著/技術評論社)
AI wiki 記事一覧 †
| 分散人工知能 | 汎用人工知能 | 特化型人工知能 |
| 自律型AI | 環境認識 | 意思決定アルゴリズム |
| メタAI | プロシージャル | パス検索 |
| ニューラルネットワーク | ナビゲーションAI | ナビゲーション・メッシュ |
| ディープラーニング | スクリプテッドAI | シンボリズム |
| コネクショニズム | ゲームAIの歴史 | キャラクターAI |
| エージェント・アーキテクチャー | ウェイポイントグラフ | アフォーダンス |









コメント